
If you haven’t heard already, DeepSeek is quickly becoming the latest catchphrase in tech. So much so that other Gen AI brands are clamoring to say that their product or LLM model is more powerful or has better reasoning and so forth. We can’t help but feel that many are losing sight of why DeepSeek made such a splash in the first place, so here's all you need to know about DeepSeek so far.
Why did DeepSeek make such a big name for itself?
#1. Comparable AI Performance for much less cost
DeepSeek has significantly reduced the costs associated with developing and using advanced AI models compared to platforms like ChatGPT. Training their latest model, DeepSeek-R1, cost approximately $5.6 million (~RM24.9 million), whereas similar models from competitors have training costs ranging from $100 million (~RM445 million) to $1 billion (~RM445 billion).
For users, DeepSeek offers a more affordable pricing structure. Its API services are priced at 1 yuan (~RM0.62) per million input tokens and 16 yuan (~RM9.91) per million output tokens. In contrast, other comparable models charge $15 (~RM66.8) per million input tokens and $60 (~RM267) per million output tokens.
This substantial difference in both development and usage costs makes DeepSeek a more cost-effective option for users seeking advanced AI capabilities.
[Update] As of 11 February 2025, DeepSeek has stopped promotional pricing and increased API pricing to $0.27 (~RM1.21) per million input tokens and $1.1 (~RM4.92) per million output tokens. Still fairly low by comparison but an increase nevertheless.
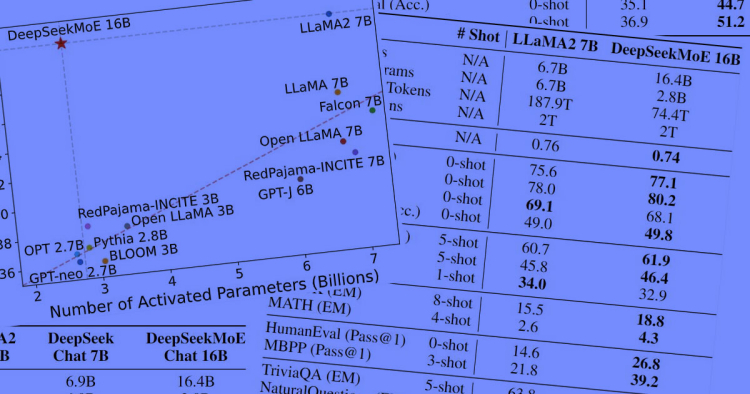
#2. Mixture-of-Experts (MoE) computational method lowers computational overhead
DeepSeek’s Mixture of Experts method improves efficiency by only calling up the experts needed as required by the prompt. This reduces costs and computational demands. It also enhances performance by using specialized "experts" for different tasks, ensuring more accurate responses. In comparison, other AIs usually go for one big expert that knows everything.
MoE also allows for better scalability, lower energy consumption, and affordability compared to more dense AI models. However, it adds training complexity due to expert routing.
#3. Significantly better energy efficiency
Since DeepSeek’s Mixture of Experts method activates only a small fraction of its parameters per prompt, this reduces computation and GPU load. This in turn lowers power consumption, decreases heat generation, and scales efficiently without increasing energy demands. This method also optimizes training by focusing only on relevant experts, cutting down computational waste.
Initial reports indicate that DeepSeek only uses up to 90% lower energy consumption and a 92% reduction in carbon footprint relative to comparable infrastructures for 20–30% better energy efficiency. This in turn makes it more sustainable.
Early adopters and current responses to DeepSeek
DeepSeek’s open source nature also means it's a lot easier to share and build upon. However, early adopters of DeepSeek have noted that while the AI does seem to deliver more human-like responses compared to the competition, it may lack in terms of general knowledge. This indicates that the training for DeepSeek’s LLM models could be not as thorough as others, which could also indicate why it costs only $5.6 million (~RM24.9 million) compared to the usual 100 million (~RM445 million).
Other responses have been mixed. While it became the top-rated AI Assistant on Apple’s App Store in the US, it also got the ‘Tik Tok’ treatment in Italy over privacy concerns. Back in China, it seems to have triggered a price war from Chinese tech companies that offer similar services. In addition, DeepSeek themselves also reported being targeted by cyber attacks, reportedly from the US.
AMD has already revealed how to run DeepSeek off of an AMD + Radeon powered system while NVIDIA’s stocks have seen a significant drop.

Conclusion - A sign of things to come?
Thanks to their innovative methods and energy efficiency, we fully expect DeepSeek to remain popular for a while yet. It would be great if other AI competitors didn't try to spin their much better pros over DeepSeek's obvious cons. Rather than that, we’re looking forward to the AI company that will solve Gen AI’s energy efficiency and other shortcomings better.
However, with the way certain parties want to maintain market dominance through control of AI chip supply, it seems as if countries like Malaysia who are interested in AI may have no other choice but to focus on DeepSeek and other less resource hungry AI models.

According to DeepSeek themselves, they just want to reach AGI or Artificial General Intelligence. Ideally, we’d all get to AGI a lot faster if we all worked together but some parties are just stuck on the idea of dominance. As if their perceived 5G dominance did anything for them in the long run anyway.
In any case, what do you TechNavers think about DeepSeek? Has anyone tried it yet? Share your thoughts in the comments below and stay tuned to TechNave.com




COMMENTS