
The first time I tried Google Veo 3 and Flow to make a more than 8-seconds video, I came up against problems with consistency. This meant that throughout my videos, my character sometimes didn't have the same clothes, hairstyle or even voice.
While you can reduce the chances of inconsistency by using the Frame-to-Video function to upload an image of the character you intend to use, this costs a lot more AI credits. And to top it off, it can still be somewhat inconsistent. To solve this, we made this guide on How to get consistent characters in Google Veo 3 and Flow, so do read on.

You can see that the character does not have the same hair style, nor is she wearing the same clothes and in the video she also has a different voice
What can you do? How about the built-in features?
Google has already created features built into Flow to help solve these problems of consistency. These include Frame-to-Video, Extend-to-Video and Ingredients-to-Video. Unfortunately, Ingredients-to-Video is only for Ultra subscribers, so we didn't test it.
Frame-to-Video on the other hand, costs a whopping 100 AI credits for each video generation. While it does make more consistent characters by supplying an image of the character you created, you could use up your whole monthly quota of 1000 AI credits in just 10 or so video generations.
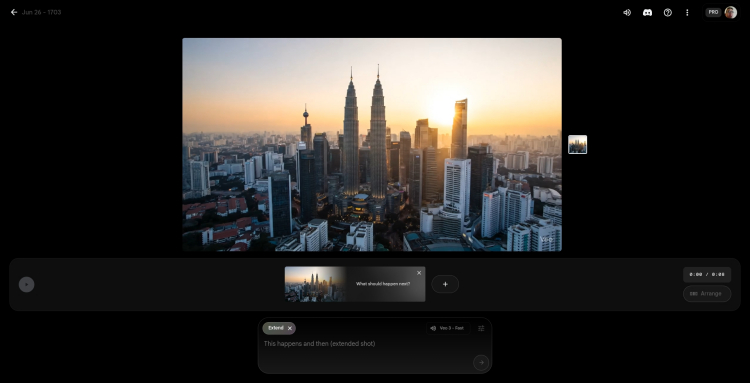
Extend-to-Video lets you build upon the previous image without having to reiterate the same prompt
Thankfully, Extend-to-Video lets you continue the scene it is extended from without having to reiterate the prompt from before. This only costs 10 AI credits but at the moment it only supports Veo 2 and not Veo 3, so there is no automatic voiceover or audio. If you do use it, you'd have to put in the audio or voiceover yourself later.
In the end, text-to-video remains the most cost effective method of crafting a video using Google Flow at just 10 AI credits per generation. It also offers a bit more control and more features. However, if our previous attempts are any indication, it isn't as easy as just typing anything you want in the prompt box.
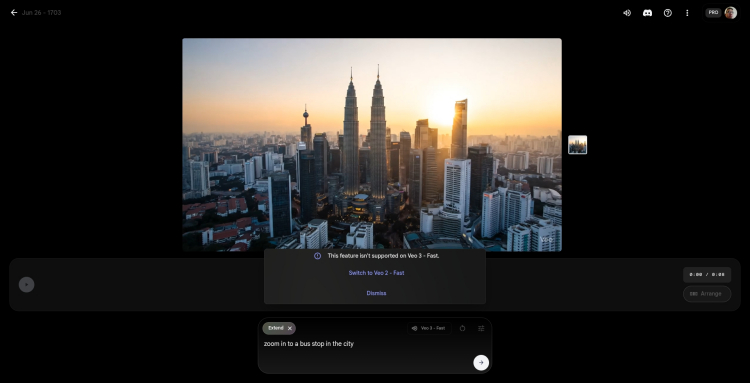
Unfortunately, Extend-to-Video is not supported by Veo 3
How to make text-to-video consistent in Flow?
Answering the question "Who actually needs a transparent smartphone?" is Nina, our first consistent character in Google Veo 3 / Flow
Taking a page from others who have found the way, apparently, you need to phrase the description according to how Google Veo 3 would describe it. To do this you need to use Google Whisk to help come up with the description and then use Gemini to create a more consistent prompt.
Here are the steps we did to make consistent text-to-video in Google Flow:
- Use Google Whisk to generate an image of the object you want to be consistent.
- Download that image and copy the prompt used for it.
- Upload that image to the Subject window in Google Whisk, tap the pen icon for how it would describe it and copy this.
- Give the consistent object a name, then paste those copied descriptions into the prompt below.
- Run this prompt in Gemini, upload the image you generated and get the consistent description.
- Use this description in the new Google Flow prompts.
- Generate the videos in Flow accordingly and edit the videos as necessary.

This is the image of Nina that I came up with in Google Whisk
Here is the overall prompt format:
Here is a prompt I wrote in Whisk: [My initial description]
Here is the image description received for the image (attached): [Google Whisk description]
I would like a detailed Veo 3 description of just the [consistent object] that I can use in a template for building prompts where I will try to place her in a consistent looking way.
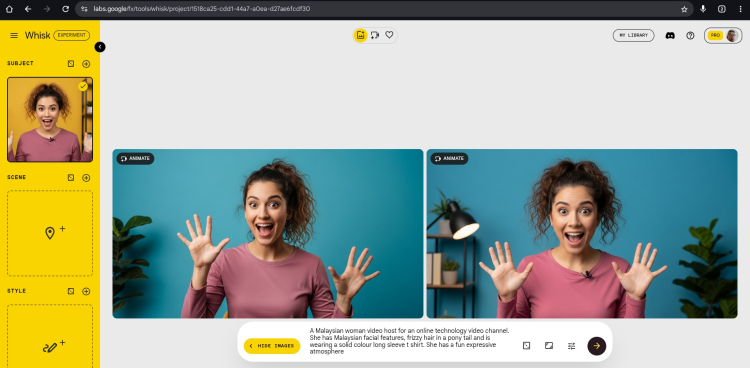
In Google Whisk, upload Nina's image in the Subject window and then tap the pen icon for her description
Here is the filled up prompt which I ran in Gemini with the uploaded image of Nina:
Here is a prompt I wrote in Whisk: A Malaysian woman video host for an online technology video channel. She has Malaysian facial features, frizzy hair in a pony tail and is wearing a solid colour long sleeve t-shirt. She has a fun expressive atmosphere
Here is the image description received for the image (attached): A woman with light brown skin, appearing to be in her 20s, is centered in a medium shot, facing forward with a surprised expression. Her mouth is open wide in an "O" shape, revealing her teeth, and her eyes are wide and bright. Her dark brown, curly hair is pulled up into a high ponytail, with some strands escaping around her face, framing her eyes and forehead. Her eyebrows are dark and well-defined, and she has visible eyelashes. She is wearing a simple, long-sleeved, scoop-neck top in a muted rose or dusty pink color. A small, black lavalier microphone is clipped to the center of her collarbone area. Both of her hands are raised to shoulder height, palms facing outward, fingers splayed as if in a gesture of disbelief or excitement. The background is a vibrant, solid yellow wall, creating a stark contrast with her clothing and hair. To the left of the woman, a portion of a green potted plant with large leaves is visible. To the right, a dark, open shelving unit with several books and other decorative items is partially visible. The lighting is bright and even, illuminating her face and the yellow background.
I would like a detailed Veo 3 description of just the woman that I can use in a template for building prompts where I will try to place her in a consistent looking way.
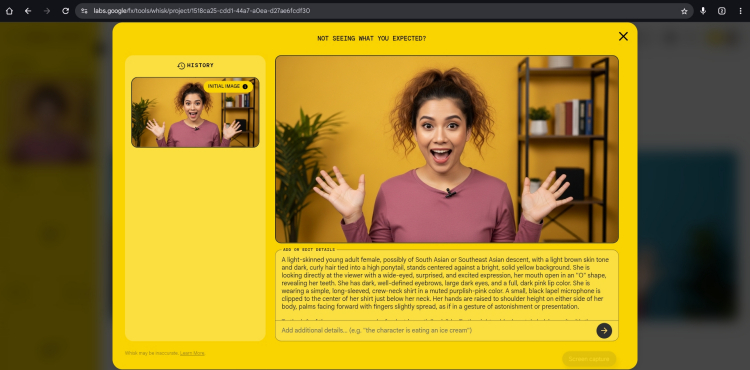
This is the image description according to Google Whisk
Here is the resulting Veo 3 description from Gemini:
A Malaysian woman in her 20s with light brown skin, dark brown curly hair in a high ponytail, and dark, well-defined eyebrows. She is wearing a muted rose or dusty pink long-sleeved, scoop-neck top with a small, black lavalier microphone clipped to the center of her collarbone area. Her hands are raised to shoulder height, palms facing outward, fingers splayed.
Here is the prompt for Scene 1 of the video above:
Scene 1: Host Wonderingly Talking About the Transparent Phone
A cinematic medium shot of Nina, a Malaysian woman in her 20s with light brown skin, dark brown curly hair in a high ponytail, and dark, well-defined eyebrows. She is wearing a muted rose or dusty pink long-sleeved, scoop-neck top with a small, black lavalier microphone clipped to the center of her collarbone area. Her hands are raised to shoulder height, palms facing outward, fingers splayed.
The background is a softly blurred, clean, modern tech studio with professional, diffused lighting and perhaps a subtle hint of sleek tech gadgets in the background.
Nina speaks incredulously, her voice is a clear, friendly female voice in Malaysian English with a moderate pace and enthusiastic tone, suitable for hosting an online technology video channel: "Wow, we never thought someone would actually do this!"
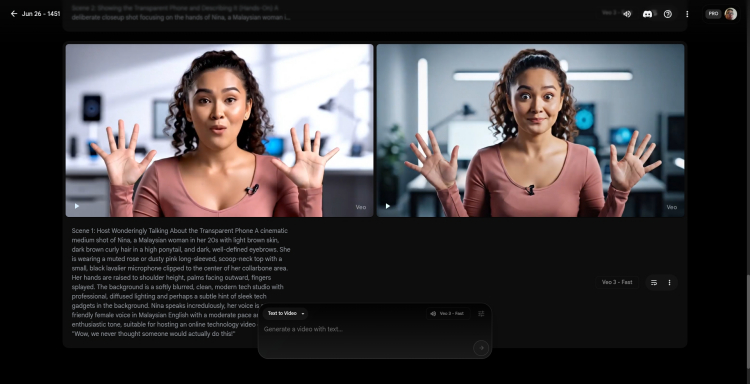
You can see that I have described how the camera should view our character Nina, who I have given a name in the prompt. The Veo 3 description has been included into the prompt along with a description of the background and her voice. I then continued using these in the prompts for the next scenes.
Despite all this, not everything went well. I still got 1 generation with a completely different character and 1 generation where the dreaded inaccurate captions appeared. Still, the character Nina was quite consistently generated. I then upscaled the videos to 1080p, downloaded them separately and edited them in Samsung Studio to become the video as above.
So, how did your attempts at consistency turn out in Google Flow and Veo 3? We hope our guide helped. Please share your experiences in the comments below and stay tuned to TechNave.com for more tech articles and guides.




COMMENTS